Review of Data Descriptor a Multimodal Dataset for Various Forms of Distracted Driving
1. Introduction
Co-ordinate to the World Health System (WHO) global status report [1], road traffic accidents cause 1.35 meg deaths each twelvemonth. This is nearly 3700 people dying on the earth's roads every day. The most heart-breaking statistic is that route traffic injury has become the leading crusade of death among people aged 5 to 29 [two]. The investigation [3] for the crusade of car collisions shows that 94% of route traffic accidents in the United states are caused by human operations and errors. Among them, distracted driving, which can reduce the driver's reaction speed, is the most dangerous behavior. In 2018 alone, 2841 people died in traffic collisions on Us roads due to commuter distraction [4].
The impacts of distracted behavior of drivers are multifaceted [5], including visual behavior, operating behavior, driving pressure, and the power to perceive danger, etc. According to the definition of the National Highway Traffic Safety Administration (NHTSA) [6], distracted driving refers to any action that can divert attending abroad from driving, including (a) talking or texting on a phone, (b) eating and drinking, (c) talking to others in the vehicle, or (d) using radio, entertainment or navigation system.
Distracted driving detection can be used to give early warning of dangerous driving behavior, including using a mobile phone to call or transport text messages, using navigation applications or choosing to play music, etc. [7]. Distracted driving detection methods are mainly based on the driver'southward facial expression, head operation, line of sight or torso operation [8]. Through visual tracking, target detection, motion recognition and other technologies, the driver's driving behavior and physiological state can be detected.
In the early days, researchers mainly focused on beliefs analysis based on the commuter'south line-of-sight direction through the eye, confront, and caput operation. In 2002, Liu et al. [9] proposed a method of tracking the driver's facial area and used the yaw direction bending to estimate the driver'due south facial functioning to detect the driver's facial orientation. Eren et al. [10] successfully developed a driver's facial operation detection organisation based on binocular stereo vision, using hidden Markov models to predict the driver'due south facial performance in 2007.
Later, with the evolution of machine learning technology and the public of driving behavior datasets, increasing studies were added to analyze the driver'southward phone calling, drinking, eating and other unsafe driving behaviors. Southeast University driving posture (SUE-DP) dataset [eleven] was proposed in 2011. The experiment collected four types of distracted driving behaviors: "grasping the steering wheel", "operating the shift lever", "eating," and "talking on a cellular phone". A serial of studies have been conducted based on the SUE-DP dataset: Zhao [12] used the multiwavelet transform method and the multilayer perceptron (MLP) classifier to recognize iv predefined driving postures and obtained an accuracy of ninety.61%. Zhao et al. [eleven] introduced a contourlet transform method for characteristic extraction and achieved 90.63% nomenclature accurateness. Subsequently. Chihang [13] used support vector machines (SVM) algorithm with an intersection kernel for obtaining 94.25% accuracy. In 2013, The epitome pyramid histogram of oriented gradients (PHOG) features and edge features [14] were extracted comprehensively to increase the nomenclature accuracy to 94.75% within MLP. In 2014, Yan [15] extracted the PHOG features of historical moving images containing time information and obtained 96.56% accuracy through the random forests (RF) algorithm.
Recently, with the development of deep learning classification and detection engineering, increasing researchers analyzed driving behavior through convolutional neural networks (CNNs). More researchers accept also begun to build their own research datasets. A combination of pre-trained sparse filters and convolutional neural networks [xvi] was used to increase the classification accuracy of the SUE-DP dataset to 99.78%. Yan [17] improved the conventional regions with CNNs features (R-CNN) framework past replacing traditional pare-similar region extractor algorithms and obtained a classification accuracy of 97.76% on the SUE-DP dataset. Liu [18] used an improved dual-input deep three-dimensional convolutional network structure algorithm based on a three-dimensional convolutional neural network (3DCNN), achieving 98.41% accuracy on the rails transit dataset. Jin [19] trained two independent convolutional neural networks past optimizing the size and number of convolution kernels, which can effectively identify mobile phones and hands in existent time achieving 144 fps and an accurateness of 95.vii% for mobile phone usage on the self-built dataset. Multiscale attending convolutional neural network [twenty] was proposed commuter action recognition.
More recent datasets and studies include: The StateFarm dataset was published in the 2016 Kaggle distracted driving recognition competition [21] with ten types of distracted driving behaviors. Alotaibi [22] used an improved multiscale Inception model with a classification accuracy of 96.23% on the StateFarm dataset. Lu et al. [23] used the improved deformable and dilated faster RCNN (DD-RCNN) structure to obtain an accurateness of 92.ii%. Valeriano [24] and Moslemi [25] used the 3DCNN algorithm to recognize driving behavior and got 96.67% and 94.4% accuracy rates, respectively. In 2018, Eraqi and others [26,27] proposed the American University in Cairo (AUC) distracted driving dataset with reference to the 10 distracted postures divers in the StateFarm dataset. The ASUS ZenPhone close-range camera and DS325 Sony DepthSense photographic camera were used to collect driving images and videos of 44 volunteers from 7 countries. The cameras were stock-still to the roof handle on the height of the front passenger'due south seat. The resolution of the data is 1080 × 1920 or 640 × 480. A total of 17,308 frames were collected for the dataset, which was finally annotated to x kinds of distracted driving behaviors: safety driving (3686), texting using the right hand (1974), talking on the phone using the right paw (1223), texting using left hand (1301), talking on the telephone using left hand (1361), operating the radio (1220), drinking (1612), reaching behind (1159), hair and makeup (1202), and talking to the passenger (2568). The dataset was randomly divided into 75% for training and 25% for test data. A genetically weighted ensemble of convolutional neural networks combined with the face, mitt, and skin regions was proposed to obtain an accuracy of 95.98% with the AUC dataset. Bhakti and others [28] used the AUC dataset to reach 96.31% accurateness through improved visual geometry grouping 16 (VGG-16) with regularization methods.
The collection of the dataset mainly used the camera to obtain images of the driver'south driving process. During the collection process, it was usually recommended that the driver perform distracting subtasks to simulate distracting driving. The distracted driving methods were mainly based on the driver's facial expression, head performance, line of sight, or torso operation for feature extraction. Machine-learning methods and deep learning CNN methods were used for distracting driving recognition. However, the existing datasets and related analysis methods still encounter some problems in the research: on 1 hand, the current distracted driving enquiry mainly judges driving behavior by the commuter'southward facial and head management, hand movements, or peel segmentation information. Still, the judgment of single local information is prone to classification errors. On the other hand, due to the differences in the resolution, wide-angle, installation position, and installation angle of the camera in different datasets, or the differences in the position of the seat and steering wheel, the position and angle of each driver in the dataset volition exist different, leading to the images in the dataset have dissimilar redundant information.
Two-phase deep architecture methods [29] were usually used in image classification of remotely collected images. A mutual approach in the literature was employing CNNs for feature extraction to reduce the dimensionality [30]. Data enhancement methods [31] such as flip, rotation, ingather, interpolation and color convert [32] were too often used in the first stage of processing to increase robustness. In order to build a more robust driver behavior analysis model and improve the accurateness of dataset classification, this paper designs a information augmentation preprocessing model for commuter beliefs central areas based on faster R-CNN [33] detection algorithms to meliorate the accuracy of the algorithm learned from the two-stage depth architecture method. The classification results with data augmentation are verified based on AlexNet [34], InceptionV4 [35] and Xception [36], respectively. To reach the all-time performance, transfer learning [37] was practical in training. The American University in Cairo distracted driver (AUC) dataset is used for the experiments.
The master contributions of this paper are summarized in the following three parts:
(i) First, the class activation mapping method [33] was used to analyze the driving operation key areas in the images.
(2) Then, in order to heighten the dataset, the image detection algorithm faster R-CNN was used to generate the new driving operation area (DOA) dataset. The driving operation areas were labeled on 2000 images using the AUC dataset to institute the training driving functioning areas detection dataset for faster R-CNN grooming. Within the trained faster R-CNN model, all the AUC dataset images were tested to obtain the preprocessed AUC new DOA classification dataset, which was consistent with the original AUC dataset at the classification storage method and naming method.
(3) Side by side, a classification model was congenital to process the AUC original dataset and the DOA dataset. The experiments were tested with AlexNet, InceptionV4 and Xception separately to get the best effect.
(4) Finally, the trained nomenclature method was used to test our own dataset, which was established with a wide-angle photographic camera different from the close-range photographic camera in the AUC dataset.
The framework of classification model with data augmentation method is shown in Effigy 1. Experiments proved that the classification accuracy of the method proposed in this newspaper is up to 96.97%, which tin meliorate the accurateness of nomenclature.
2. Materials and Methods
two.1. Driving Operation Area
In order to effectively discover which areas of the image the network focuses on, this paper used slope-weighted class activation mapping (grad-CAM) [38] to visually display the features regions found by the Xception nomenclature network, which displayed in the form of a grade-specific saliency map or "heat map" for curt. Figure two shows the grad-CAM result of ten different driving behaviors, which can be used to visually evaluate the cardinal feature regions of the image. The distribution of the ribbon color from crimson to blueish that you can run across the mapping human relationship between weight and colour. The red expanse in the activation map represents the higher basis expanse for the model to make nomenclature decisions.
According to the grad-CAM effect, the commuter's upper body behaviors in the vehicle environment decide the distracted driving classification outcome, which means that the background and legs that are not related to the commuter'south performance are all redundant data in the feature extraction. Nosotros proposed the concept of the driving operation surface area (DOA), including the steering wheel and the driver's upper body, which include the head, torso, and artillery, to draw the features related to the driver's driving behavior. The expanse in the carmine box shown in Figure i is what we defined DOA.
ii.2. Methods for Data Augmentation
Due to the stock-still nature of the distracted driving background, traditional data augmentation methods (such as flipping, rotation, trimming, and interpolation) upshot in unrealistic scenes, which will crusade information distortion and increase irrelevant information. This paper proposed the data augmentation method based on the primal area of driving behavior. The mature paradigm detection convolutional network model is used for the data augmentation method. The AUC dataset was enhanced based on the DOA to obtain a new dataset. Classification modules were introduced to classify the original dataset and the new dataset.
Co-ordinate to the requirements of the image detection model for the dataset, we randomly selected 2000 images from the AUC dataset to relabel the driving performance area using "labelImg" software tool. The labeling area included the steering bike and the driver's upper body, including the head, torso, and arms. The annotation file was saved as an XML file in accord with the Pascal visual object classes (PASCAL VOC) dataset format. The epitome detection convolutional network model was used to extract the driving functioning area.
faster R-CNN [33] was chosen as the paradigm detection model for feature extraction. faster R-CNN creatively used region proposal networks to generate proposals and shared the convolutional network with the target detection network, which can reduce the number of proposals from the original well-nigh 2000 to 300 and improve the quality of the suggested frames. The algorithm won many firsts in the ImageNet Large-scale visual recognition competition (ILSVRC) and the common objects in context (COCO) competitions that year, even so used frequently by studiers now.
faster R-CNN model was trained with the labeled information; then, the trained faster R-CNN model was used to infer all the AUC dataset images to obtain the preprocessed new DOA classification dataset. The classification and naming of the DOA dataset were consequent with the original AUC dataset.
ii.3. Methods for CNN Nomenclature
This paper used the mature image detection convolutional network model for the data augmentation method. Classic models such as Alexnet [34], InceptionV4 [35], and Xception [36] had been widely used in image classification research in contempo years. AlexNet successfully practical rectified linear units (ReLU), dropout and local response normalization (LRN) in CNN. The Inception network started from GoogLeNet in 2014, which had gone through several iterations of versions up to the latest InceptionV4. Xception was another improvement proposed past Google after Inception.
Transfer learning, whose initial weights of each model came from the weights obtained by pre-preparation on ImageNet, was used in our classification exam to train the AUC dataset by optimizing the parameters to go the best outcome.
The AUC dataset was enhanced based on the DOA to obtain a new dataset. Classification modules were introduced to classify the original dataset and the new dataset. The nomenclature framework with the data augmentation method is shown in Figure 1.
ii.four. Wide-Angle Dataset
In order to farther verify the generalization power of our methods, A Wide-angle distracted driving dataset was collected for verification. Referring to the drove methods of the State Farm dataset and the AUC dataset, we fixed the camera to the car roof handle on top of the front passenger's seat. Fourteen volunteers sat in the car to simulate distracted driving as required in both mean solar day and night scenes. Some volunteers participated in more than one collection session at different times of solar day, driving roads and wearing different clothes. The 360′s G600 recorder, which has a resolution of 1920 × 1080 and a wide-angle of 139 degrees, was used in the collection. In order to simulate a natural driving scene as much equally possible; in some cases, there were other passengers in the automobile during the drove process.
The data were nerveless in a video format with the size of 1920 × 1080 and so cut into individual images. Our dataset finally collected 2200 pictures of ten kinds of distracted driving behaviors: safe driving (291), texting using the right mitt (224), talking on the telephone using the right mitt (236), texting using left mitt (218), talking on the phone using left hand (211), operating the radio (203), drinking (198), reaching behind (196), hair and makeup (182), and talking to the rider (241). Function of the images of the wide-angle dataset is shown in Figure 3.
3. Results
The experiments in this commodity were based on the PaddlePaddle framework and Python design, with the hardware environs using a Linux server with Ubuntu 16.04. A single NVIDIA GeForce GTX, 1080 Ti GPU with 12 GB RAM, was used in the experiments.
3.1. Results for Driving Operation Area Extraction
The labeled driving dataset with 2000 images was split into a preparation set and a validation set with a ratio of 8:ii for validating the detection model performance. Using the same grooming strategy as Detection, the dataset was trained with the batch size of 8, the learning rate of 0.001, and the training iterations of 50,000. The momentum 0.9 with a weight decay of 0.0001 for stochastic gradient descent (SGD) was used to converge the model. The Resnet was used for the courage network. The Resnet weights pre-trained on ImageNet model was used for initialization.
Table 1 is the result of driving operation area extraction with the detection model. Faster R-CNN model was evaluated and compared with the other two models: y'all only look once (YOLO) [39] and single shot multibox detector (SSD) [40] models. According to the result in Table ane, the accuracy of faster R-CNN detection is 0.6271, and fps is 10.fifty which can meet real-time requirements. Considering the accuracy requirements, the faster R-CNN was called as the detection model in our experiments. YOLOV3 and SSD models can be used as real-time detection arrangement.
Figure 4 shows ten dissimilar types of driving functioning area detection results. Comparing Figure 2 and Figure 4, the key regions are extracted by the image detection model.
Then the trained weights of faster R-CNN were used to detect the key areas of driving behavior in the AUC dataset, and generate a dataset of driving operation expanse, which was recorded as the DOA dataset, which classification and naming methods were the same as the original AUC dataset.
three.two. Results for CNN Classification
In the experiment, the dataset of AUC and DOA were both 12,997 images of grooming set and 4331 images of examination gear up. The paradigm nomenclature model AlexNet, InceptionV4 and Xception were used to train with image shape of 224 × 224 × 3, the learning rate of 0.001, batch size of 32, and epoch of 100. The superlative-ane accurateness was selected to evaluate the performance of the models. We performed 3 rounds of verification. Table 2 summarizes the test results for loss and accuracy of three different convolutional network models: AlexNet, InceptionV4, and Xception.
As tin can be seen from Table 2, the test top-1 accuracy of the AlexNet, InceptionV4 and Xception on the AUC dataset are 0.9314, 0.9506 and 0.9531, respectively, and the test results on the DOA dataset are 0.9386, 0.9572 and 0.9655, which ways the DOA dataset has higher detection accurateness and lower loss value than the original AUC dataset.
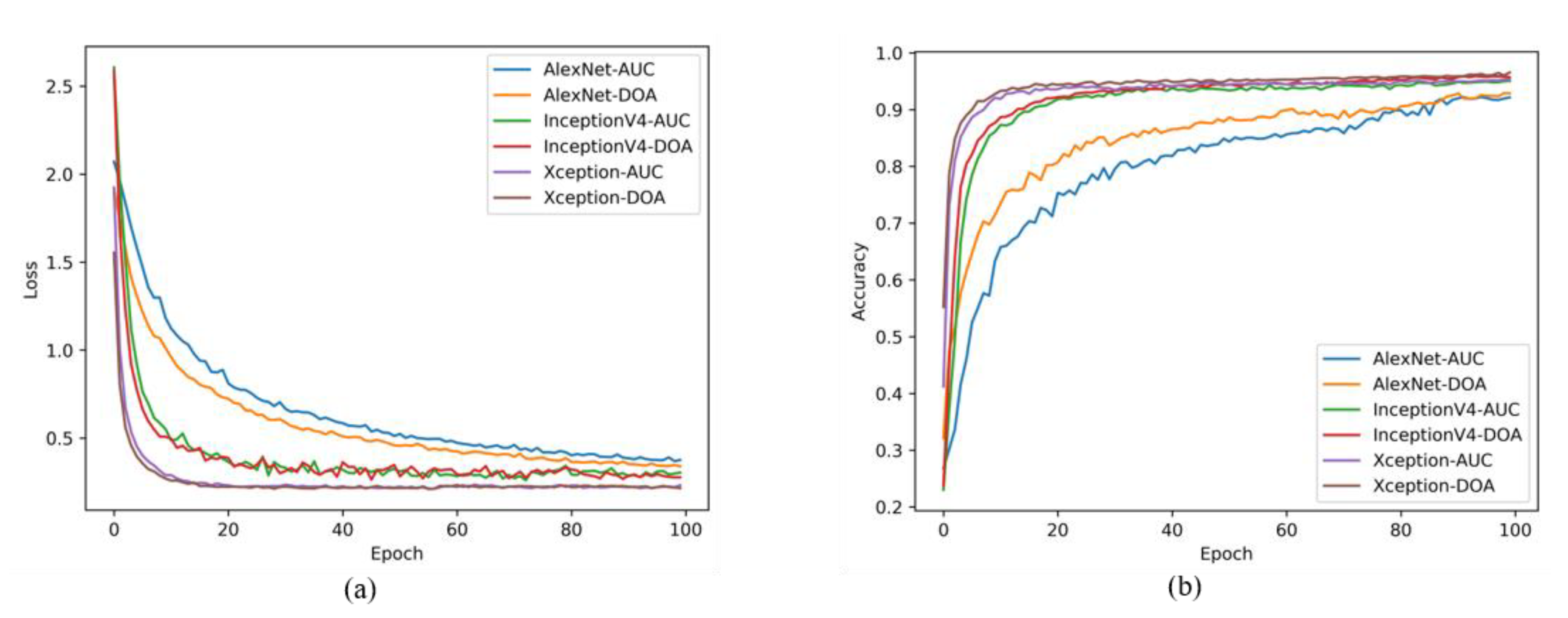
Figure five shows the change for loss and accuracy of each method in each epoch stage. When the epoch is 10, the loss and accuracy of the DOA dataset with the Xception model begin to stabilize, and when the epoch is 14, the original AUC dataset loss and accurateness with the Xception model begin to stabilize. Moreover, The loss values in the DOA-based results are lower than original AUC dataset. Information technology tin be seen from the testing loss and accurateness curves with varying epochs, the loss of DOA dataset corresponding to the key areas of driving behavior converges faster than the original AUC dataset, and the detection accuracy rises faster too.
Finally, the DOA training fix obtained through data augmentation and the original AUC training set were merged to expand the dataset. The final classification accuracy is shown in Table iii. Amongst the iii classification models, the baseline with Xception has the smallest fluctuation, the lowest loss event, and the highest accuracy, which is the near suitable for the benchmark model of this classification. For more than evaluation, Figure half-dozen is the confusion matrix for the classification results of the x distracting behaviors with Xception. Using the given confusion matrix, ane can check that many categories tin can easily be mistaken for (c0) "safe driving". Moreover, the near confusing functioning is (c8) "hair and makeup". It may exist due to the position of "easily on the wheel" in both classes.
Our distracted driver detection result was compared with earlier methods in the literature. Compared with some early methods, our method can be applied to the preprocessing stage. We achieve the best accuracy than earlier methods equally shown in Table iv. Amid them, the tiptop-1 accurateness of our module based on Xception is finally 0.9697, which is i.66% higher than the nomenclature accurateness of origin AUC dataset.
3.3. Tests on Wide-Angle Dataset
Due to the loftier correlation between the preparation and test data of the AUC dataset, this makes the detection of driving distraction an easier problem. Therefore, the newly collected wide-angle dataset was used to verify the generalization ability of our method. The wide-angle dataset contains fourteen drivers (2200 samples). The broad-angle dataset was used to verify the feasibility of our proposed method, particularly for datasets with a relatively small proportion of drivers. The trained model on the AUC dataset was used in the verification for the wide-angle dataset direct. Referring to the performance of the previous experiment with Xception-based model, this paper used the Xception-based model to verify the generalization ability.
Table 5 shows the verification result of the dataset captured by the broad-angle camera. The classification top-1 accuracy of the model is greater than eighty%, which verifies a relatively good generalization ability. In addition, the classification results after extracting the fundamental areas of the driver operation are significantly ameliorate than the original data nomenclature results. It proves the necessity of extracting key areas of drivers in distracted driving detection.
iv. Discussion
In practical applications, due to the difference in the installation position and resolution of the camera, and the divergence in the position of the commuter's seat and steering bike, the driver'south distribution position and bending in the image volition be different. The difference in the proportion of the driver'south operating area in the image will cause many pixels in the epitome of the collected dataset to be redundant data. This article focuses on improving the robustness and accuracy of distracted driving detection.
First, with the labeled data, faster R-CNN was used to notice the key areas of driving beliefs. The extraction of DOA was a large target detection for CNN, and the full general faster R-CNN has been able to reach good accuracy. It can be seen from the experimental results that this method can extract key data and tin can be used in the start stage of distracted driving detection. Comparing with grad-CAM activation maps, information technology can exist seen that our method was especially helpful for driving beliefs detection in complex backgrounds.
Second, the convolutional neural network classification model was used to test the loss and accuracy of the AUC dataset and the DOA dataset. Information technology tin can be seen from the result that the DOA dataset has higher detection accuracy and lower loss value than the original AUC dataset. Testing with the combined dataset of AUC and DOA, the experiment got a 96.97% top-1 accurateness. Compared with some early on methods in the literature, our method can extract the overall characteristics of central areas of driving beliefs. The loss of InceptionV4 and Xception dropped to a ameliorate result when the epoch was 4, and reached relatively stable when the epoch reached 40. The results showed the effectiveness of transfer learning for CNN models.
3rd, The wide-angle dataset nerveless by bodily scene was used to verify our method. Our results demonstrated that detect the key areas of driving behavior has a great significance for driving behavior analysis of wide-angle camera shooting and long-range shooting.
It can find that if the extracted features come from the entire paradigm, which ways all the information in the paradigm (regardless of whether information technology is related to driving behavior) are used equally a preparation input, the upshot will lead to more redundant information and larger calculation. Considering the diversity of the driver's position and the complication of the cab environs, our method is suitable for applied awarding fields.
5. Conclusions
Distracted driving detection has become a major research in transportation safety due to the increasing use of infotainment components in vehicles. This paper proposed a data augmentation method for driving position area with the faster R-CNN module. The convolutional neural network classification model was used to place ten distracting behaviors in the AUC dataset, reaching the top-1 accuracy of 96.97%. Extensive results carried out show that our method improves the accuracy of the classification and has potent generalization ability. The experimental results also showed that the proposed method was able to extract key information. This provided a path for the preprocessing stage of driving behavior analysis.
In the future, the following aspects can be continued for further inquiry:
Kickoff, more than distracted driving datasets with multi-angle and night scenarios should be nerveless and published for more comprehensive research. We demand to verify our model on more practical large-scale datasets.
2d, the current nomenclature algorithm divides dangerous driving behaviors into multiple categories, simply in actual driving behaviors, multiple dangerous behaviors may co-be, such as watching around when making a call. We can utilize detection modes such as YOLO (or any other object detector) to discover the confront, paw, and other information on the footing of the work of DOA for more driving behavior identification.
Author Contributions
Conceptualization, J.Due west. and J.Z.; methodology, J.W.; software, J.W.; validation, J.W.; resources, J.Due west.; writing—original draft preparation, J.West.; writing—review and editing, F.L.; funding acquisition, Z.Due west. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
This project is supported by the Internet of Vehicles Shared Data Center and Operation Management Cloud Service Platform of Anhui Province.
Conflicts of Interest
The authors declare no disharmonize of interest.
References
- World Wellness Organization. Global Status Study on Road Safety 2018: Summary; Globe Health Arrangement: Geneva, Switzerland, 2018. [Google Scholar]
- Peden, M. Global collaboration on road traffic injury prevention. Int. J. Inj. Control Saf. Promot. 2005, 12, 85–91. [Google Scholar] [CrossRef]
- Singh, S. Critical Reasons for Crashes Investigated in the National Motor Vehicle Crash Causation Survey; National Highway Traffic Safety Administration: Washington, DC, USA, 2015. [Google Scholar]
- Vasilash, G.Due south. Lark and Gamble. Automot. Des. Prod. 2018, 130, 6. [Google Scholar]
- Kaber, D.B.; Liang, Y.; Zhang, Y.; Rogers, M.L.; Gangakhedkar, S. Driver performance effects of simultaneous visual and cognitive distraction and adaptation beliefs. Transp. Res. Part F-Traffic Psychol. Behav. 2012, 15, 491–501. [Google Scholar] [CrossRef]
- Strickland, D. How Autonomous Vehicles Will Shape the Future of Surface Transportation. 2013. Available online: https://www.govinfo.gov/content/pkg/CHRG-113hhrg85609/pdf/CHRG-113hhrg85609.pdf (accessed on 21 December 2020).
- Liu, D. Driver status monitoring and early warning system based on multi-sensor fusion. In Proceedings of the 2020 International Conference on Intelligent Transportation, Big Data & Smart City (ICITBS), Vientiane, Laos, xi–12 January 2020. [Google Scholar] [CrossRef]
- Yanfei, Fifty.; Yu, Z.; Junsong, Fifty.; Jing, Southward.; Feng, F.; Jiangsheng, M. Towards Early Condition Warning for Driver'south Fatigue Based on Cognitive Beliefs Models. In Proceedings of the Digital Homo Modeling and Applications in Health, Safety, Ergonomics, and Gamble Management: 4th International Conference, DHM 2013, Held every bit Office of HCI International 2013, Las Vegas, NV, Usa, 21–26 July 2013. [Google Scholar] [CrossRef]
- Liu, X.; Zhu, Y.D.; Fujimura, K. Existent-time pose classification for driver monitoring. In Proceedings of the IEEE 5th International Briefing on Intelligent Transportation Systems, Singapore, 3–6 September 2002; pp. 174–178. [Google Scholar]
- Eren, H.; Celik, U.; Poyraz, M. Stereo vision and statistical based behaviour prediction of commuter. In Proceedings of the 2007 IEEE Intelligent Vehicles Symposium, Istanbul, Turkey, 13–15 June 2007; pp. 657–662. [Google Scholar]
- Zhao, C.H.; Zhang, B.L.; He, J.; Lian, J. Recognition of driving postures by contourlet transform and random forests. IET Intell. Transp. Syst. 2012, vi, 161–168. [Google Scholar] [CrossRef]
- Zhao, C.; Gao, Y.; He, J.; Lian, J. Recognition of driving postures by multiwavelet transform and multilayer perceptron classifier. Eng. Appl. Artif. Intell. 2012, 25, 1677–1686. [Google Scholar] [CrossRef]
- Chihang, Z.; Bailing, Z.; Jie, 50.; Jie, H.; Tao, L.; Xiaoxiao, Z. Nomenclature of Driving Postures past Support Vector Machines. In Proceedings of the 2011 Sixth International Briefing on Epitome and Graphics, Hefei, China, 12–fifteen August 2011; pp. 926–930. [Google Scholar] [CrossRef]
- Zhao, C.H.; Zhang, B.L.; Zhang, X.Z.; Zhao, S.Q.; Li, H.X. Recognition of driving postures by combined features and random subspace ensemble of multilayer perceptron classifiers. Neural Comput. Appl. 2013, 22, S175–S184. [Google Scholar] [CrossRef]
- Yan, C.; Coenen, F.; Zhang, B.50. Driving Posture Recognition by Joint Awarding of Motion History Paradigm and Pyramid histogram of Oriented Gradients. Int. J. Veh. Technol. 2014, 846–847. [Google Scholar] [CrossRef]
- Yan, C.; Zhang, B.; Coenen, F. Driving Posture Recognition past Convolutional Neural Networks. In Proceedings of the 2015 11th International Conference on Natural Ciphering (Icnc), Zhangjiajie, China, 15–17 Baronial 2015; pp. 680–685. [Google Scholar]
- Yan, S.; Teng, Y.; Smith, J.S.; Zhang, B. Driver Behavior Recognition Based on Deep Convolutional Neural Networks. In Proceedings of the 2016 12th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (Icnc-Fskd), Changsha, China, thirteen–15 August 2016; pp. 636–641. [Google Scholar]
- Liu, Y.Q.; Zhang, T.; Li, Z. 3DCNN-Based Existent-Time Driver Fatigue Behavior Detection in Urban Rail Transit. IEEE Access 2019, seven, 144648–144662. [Google Scholar] [CrossRef]
- Jin, C.C.; Zhu, Z.J.; Bai, Y.Q.; Jiang, Grand.Y.; He, A.Q. A Deep-Learning-Based Scheme for Detecting Driver Prison cell-Phone Employ. IEEE Access 2020, 8, 18580–18589. [Google Scholar] [CrossRef]
- Hu, Y.C.; Lu, M.Q.; Lu, 10.B. Characteristic refinement for image-based driver action recognition via multi-calibration attention convolutional neural network. Signal Process. Image Commun. 2020, 81. [Google Scholar] [CrossRef]
- Kaggle. State Farm Distracted Driver Detection. Available online: https://world wide web.kaggle.com/c/state-farm-distracted-commuter-detection/data (accessed on 21 December 2020).
- Alotaibi, 1000.; Alotaibi, B. Distracted commuter classification using deep learning. Signal Image Video Process. 2019. [Google Scholar] [CrossRef]
- Lu, M.Q.; Hu, Y.C.; Lu, X.B. Driver action recognition using deformable and dilated faster R-CNN with optimized region proposals. Appl. Intell. 2020, fifty, 1100–1111. [Google Scholar] [CrossRef]
- Valeriano, L.C.; Napoletano, P.; Schettini, R. Recognition of commuter distractions using deep learning. In Proceedings of the 2018 IEEE eighth International Conference on Consumer Electronics, Berlin, Germany, 2–5 September 2018. [Google Scholar]
- Moslemi, N.; Azmi, R.; Soryani, M. Driver Distraction Recognition using 3D Convolutional Neural Networks. In Proceedings of the 2019 quaternary International Conference on Pattern Recognition and Prototype Analysis, Tehran, Islamic republic of iran, 6–vii March 2019; pp. 145–151. [Google Scholar] [CrossRef]
- Eraqi, H.1000.; Abouelnaga, Y.; Saad, Grand.H.; Moustafa, One thousand.Northward. Commuter Distraction Identification with an Ensemble of Convolutional Neural Networks. J. Adv. Transp. 2019. [Google Scholar] [CrossRef]
- Abouelnaga, Y.; Eraqi, H.G.; Moustafa, M.Due north. Real-time Distracted Driver Posture Classification. arXiv 2017, arXiv:abs/1706.09498. [Google Scholar]
- Baheti, B.; Gajre, S.; Talbar, Due south.; IEEE. Detection of Distracted Driver using Convolutional Neural Network. In Proceedings of the 2018 IEEE/Cvf Briefing on Computer Vision and Pattern Recognition Workshops, Common salt Lake Urban center, Utah, USA, xviii–22 June 2018; pp. 1145–1151. [Google Scholar] [CrossRef]
- Petrovska, B.; Zdravevski, E.; Lameski, P.; Corizzo, R.; Štajduhar, I.; Lerga, J. Deep learning for feature extraction in remote sensing: A case-study of aerial scene classification. Sensors 2020, twenty, 3906. [Google Scholar] [CrossRef]
- Petrovska, B.; Atanasova-Pacemska, T.; Corizzo, R.; Mignone, P.; Lameski, P.; Zdravevski, E. Aeriform scene nomenclature through fine-tuning with adaptive learning rates and characterization smoothing. Appl. Sci. 2020, 10, 5792. [Google Scholar] [CrossRef]
- Zhao, Z.; Luo, Z.; Li, J.; Chen, C.; Piao, Y. When Self-Supervised Learning Meets Scene Classification: Remote Sensing Scene Classification Based on A Multitask Learning Framework. Remote Sens. 2020, 12, 3276. [Google Scholar] [CrossRef]
- Izadpanahkakhk, Grand.; Razavi, S.M.; Taghipour-Gorjikolaie, M.; Zahiri, S.H.; Uncini, A. Deep region of involvement and feature extraction models for palmprint verification using convolutional neural networks transfer learning. Appl. Sci. 2018, viii, 1210. [Google Scholar] [CrossRef]
- Ren, S.; He, Grand.; Girshick, R.; Sun, J. Faster R-CNN: Towards Existent-Fourth dimension Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, One thousand.Due east. ImageNet Nomenclature with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Bear on of Residual Connections on Learning. In Proceedings of the Thirty-First Aaai Conference on Bogus Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 30th IEEE/CVF Briefing on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, The states, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, Grand.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, Due west.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, Southward.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
Figure 1. The framework of the classification model with the data augmentation method.
Figure i. The framework of the classification model with the data augmentation method.
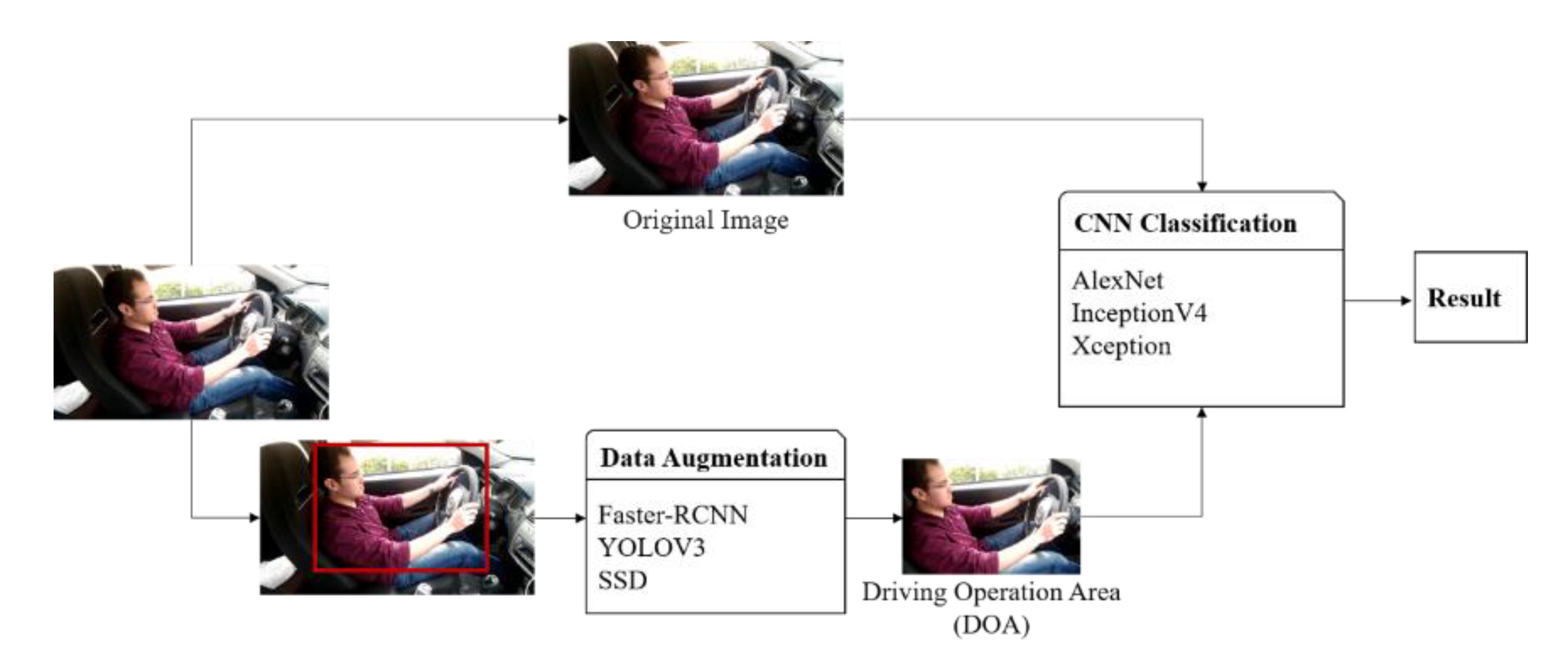
Figure 2. Grad-CAM activation maps of diverse distracted driving behaviors in the dataset.
Figure two. Grad-CAM activation maps of diverse distracted driving behaviors in the dataset.

Figure 3. Part of the images in the wide-bending dataset.
Figure 3. Office of the images in the wide-bending dataset.

Figure 4. 10 different types of driving functioning expanse (DOA) detection results.
Figure 4. Ten unlike types of driving operation area (DOA) detection results.

Figure five. Accurateness and loss of image classification result. (a) the loss of each method in each epoch phase; (b) the accuracy of each method in each epoch stage.
Effigy five. Accurateness and loss of image classification result. (a) the loss of each method in each epoch stage; (b) the accuracy of each method in each epoch phase.
Effigy 6. Confusion matrix of results Xception classification.
Figure 6. Confusion matrix of results Xception nomenclature.
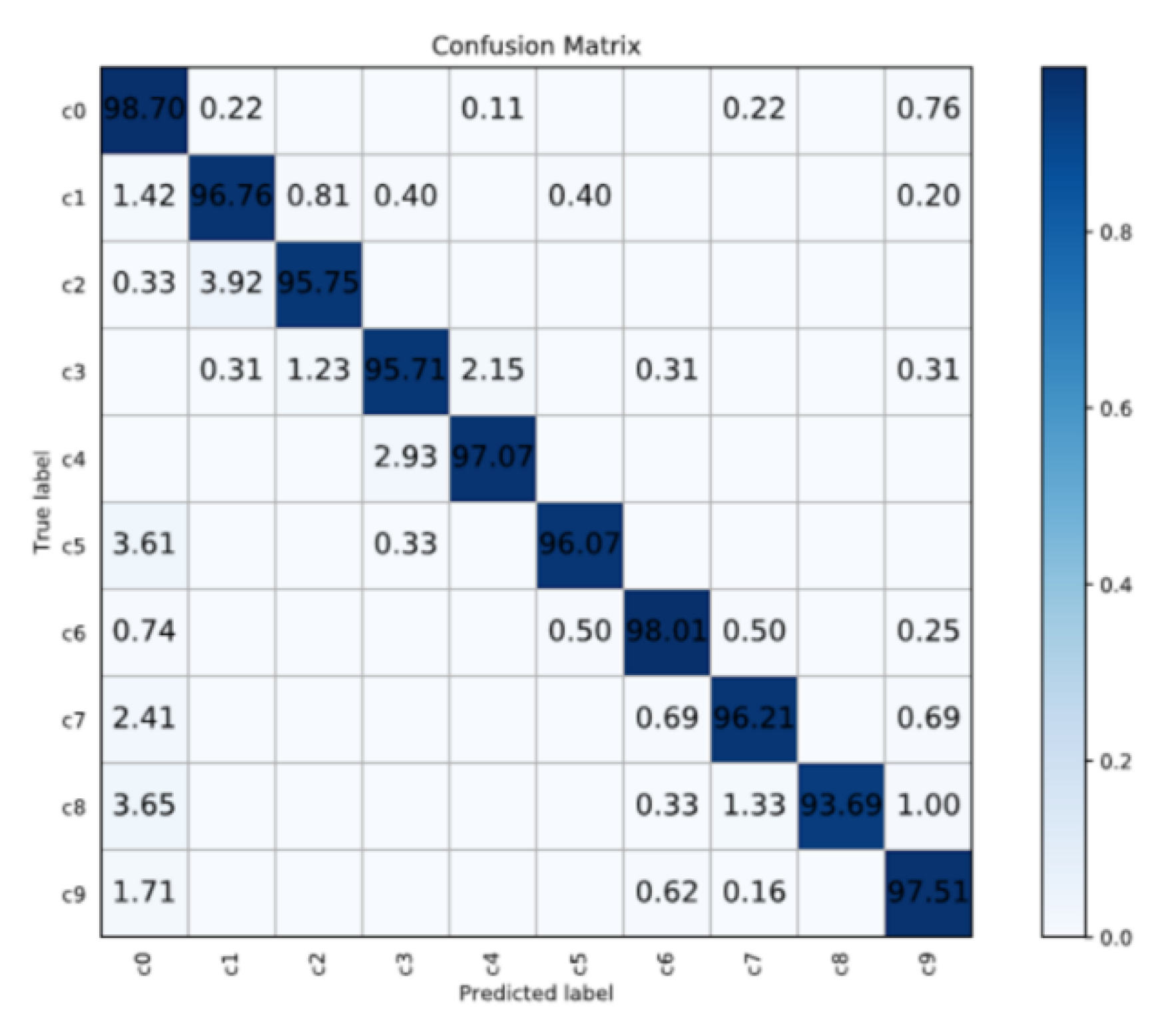
Table i. Driving operation area detection event.
Table 1. Driving functioning area detection consequence.
| Model | fps | mAP (0.75) | mAR (0.75) |
|---|---|---|---|
| faster R-CNN | 10.50 | 0.6271 | 0.6572 |
| YOLOV3 | 37.21 | 0.5390 | 0.5568 |
| SSD | 49.52 | 0.5767 | 0.5812 |
Table two. Image classification exam result with AUC and DOA dataset.
Table 2. Image classification exam upshot with AUC and DOA dataset.
| Model | Source | Loss | Top-1 Acc. |
|---|---|---|---|
| AlexNet | AUC | 0.3753 | 0.9314 |
| DOA | 0.3402 | 0.9386 | |
| InceptionV4 | AUC | 0.3041 | 0.9506 |
| DOA | 0.2771 | 0.9572 | |
| Xception | AUC | 0.2320 | 0.9531 |
| DOA | 0.2156 | 0.9655 |
Table three. Last result after confidence comparison.
Tabular array 3. Final result after confidence comparing.
| Model | Top-1 Acc. |
|---|---|
| AlexNet | 0.9396 |
| InceptionV4 | 0.9603 |
| Xception | 0.9697 |
Tabular array 4. Comparison with earlier methods from literature on AUC dataset.
Tabular array iv. Comparing with earlier methods from literature on AUC dataset.
| Model | Top-1 Acc. |
|---|---|
| GA weighted ensemble of all 5 [26] | 0.9598 |
| VGG [28] | 0.9444 |
| VGG with regularization [28] | 0.9631 |
| ResNet + HRNN + modified Inception [22] | 0.9236 |
| Our method | 0.9697 |
Tabular array five. Result on wide-angle dataset.
Table 5. Event on wide-angle dataset.
| Model | Source | Top-i Acc. |
|---|---|---|
| Xception | Wide-bending Dataset | 0.8131 |
| DOA of Wide-angle Dataset | 0.8394 |
| Publisher's Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/past/4.0/).
Source: https://www.mdpi.com/1999-5903/13/1/1/htm
0 Response to "Review of Data Descriptor a Multimodal Dataset for Various Forms of Distracted Driving"
Post a Comment